通常,只要两个操作之间的步骤是有穷的,一个多线程算法就认为可以实现为无锁(lock-free)。理论上无锁算法也早已被证明,看起来实现一个无锁算法也很简单。但其实不然,每一步都隐藏着陷阱:并发的线程可以修改共享的对象,甚至在执行一个操作时线程可以突然暂停或中止,而这是另一个线程当作好像若无其事。
线程同步是多线程程序设计的核心,传统的做法上就是代码临界区上加锁。锁可以防止多个线程同一时间进入临界区代码。在高度并发的程序里,锁可能成为严重的性能瓶颈。无锁编程的目标是不用锁也能解决并发问题。无锁编程一般依赖的是原子操作,比如“compare-and-swap”原子的执行下面的操作:
1
2
3
4
5
6
7
8
|
1 bool CompareAndSwap(Value* addr, Value oldVal, Value newVal){
2 if(*addr == oldVal){
3 *addr = newVal;
4 return true;
5 }else{
6 return false;
7 }
8 }
|
使用无锁算法的最大缺陷是:
- 无锁算法并不总是可实现的
- 无锁算法的代码很难写
- 写出正确的无锁算法代码更是难如登天
为了证明以上三点,我们来看一个错误实现的一个无锁栈(lock-free stack),可能大部分人第一次都会写出这样保护这些错误无锁栈。这个无锁栈算法主要是使用一个链表(linked-list)来存放节点,并用CompareAndSwap来修改链表的表头。 Push一个元素时,我们首先创建一个节点保存数据,并将这个节点设为栈顶,并使用CompareAndSwap将原栈顶指向新的元素。CompareAndSwap操作保证只有我们的新节点指向老的栈顶节点,才会替换老的栈顶(因为多线程可能改变老的栈顶)。当Pop一个元素时,我们快照当前的栈顶节点,然后替换当前的栈顶节点到下一个节点。我们再一次使用CompareAndSwap保证替换的节点等于快照的节点。
C++代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
1 template <class Entry>
2 class LockFreeStack{
3 struct Node{
4 Entry* entry;
5 Node* next;
6 };
7
8 Node* m_head;
9
10 void Push(Entry* e){
11 Node* n = new Node;
12 n->entry = e;
13 do{
14 n->next = m_head;
15 }while(!CompareAndSwap(&m_head, n->next, n));
16 }
17
18 Entry* Pop(){
19 Node* old_head;
20 Entry* result;
21 do{
22 old_head = m_head;
23 if(old_head == NULL){
24 return NULL;
25 }
26 }while(!CompareAndSwap(&m_head, old_head, old_head->next));
27
28 result = old_head->entry;
29 delete old_head;
30 return result;
31 }
32 }
|
遗憾的是,这个无锁栈充满的错误:
Segfault
Push操作分配内存保存节点信息,Pop操作释放这些内存。然而,线程T1在顺序执行22行和26行之间的时间里,另一个线程T2可能已经释放了这个节点,然后程序Crash了。
Corruption
仅仅对比新值与老值是否相等,CompareAndSwap方法并不能保证是否值发生了变化。假如快照在22行的值,被修改了,然后又被恢复了,然后CompareAndSwap会成功。这就是著名的ABA问题。假如栈中前两个节点是A和C,如果以下面的序列操作:
- 线程1执行Pop,并在22行读到了m_head(A),在26行读到了old_head->next(C),然后突然阻塞在执行在
CompareAndSwap之前。
- 线程2执行pop,删掉节点A。
- 线程2调用push,push了一个新节点B。
- 线程2又调用一次push,这次push的新节点正好占用了原来节点A的内存。
- 线程1被唤醒,调用
CompareAndSwap。
然后26行的CompareAndSwap会成功,虽然m_head已经被改变3次了,因为它只检测old_head是否等于m_head。这是有问题的,因为新的栈顶本应指向B,然而却指向了C。
Not lock-free
C++标准并不保证new和delete是lock-free的。一个无锁的数据结构去调用非无锁的库函数不是什么好主意,所以我们需要一个无锁的内存分配子。
Data races
当一个线程向内存中写入数据,而另一个线程同时从相同的内存读数据时,所产生的结果是未定义的,除非使用std::atomic。读和写操作都必须是原子的。在C++11以前一个通用的方法是使用volatile关键字来生命原子变量,然而这个关键字有很大的缺陷。
在我们的例子中,多个线程读栈顶指针可能会引起竞争,push和pop操作都有可能,因为其它线程可能在修改他。
Memory reordering
印象中,代码会按照我们指定的顺序执行,最少也会满足”happens before“关系。不幸的是,不管理论还是实际上,下面代码的执行可能出现x,y都是0的结果。:
C++11以前标准对于多线程是讳莫如深的,所以编译器的优化是着眼于单线程的。上面的代码,交换执行顺序,并不会影响单线程中程序的语义。所以可能会产生这种结果。
如何写正确的lock-free栈
上面大部分问题都有多种解决方案,这里我会把自己工作中使用的方法描述出来。
Segfault
解引用节点之前,必须确保该节点没有被删掉。每一个线程都有一个全局可见的"hazard pointer"。当访问一个节点之前,会先设置Hazard pointer执行这个节点。只要设置过Hazard pointer就可以保证这个节点此时还是栈顶节点。如果其它线程此时移除这个栈顶节点,要检测没有Hazard pointer指向这个节点才能清除节点的内存。
Corruption
解决ABA问题的一个方法是确保栈顶不会有同样的值两次。我们使用“tagged pointers”来确保栈头值的唯一。一个“tagged pointers”包含一个指针和64位计数器。每当栈顶变化,计数器加一。
Not lock-free
Data races
我们目前使用的是boost::atomic。现在我们使用gcc4.6也已经支持std::atomic,但实现的效率没有boost高。在gcc4.6中,所有需要原子操作的地方都被应用了memory barriers,即使本不必使用的地方。
Memory reordering
C++11为原子操作提供了一种新的内存模型和内存序语义,以解决乱序的问题。CompareAndSwap需要顺序一致性(sequentially consistent)的语义保证。顺序一致性意味着所有的线程以一种一致的次序执行操作。事实证明hazard pointers也一样需要顺序一致性保证内存语义。
如果不使用内存一致性,下面这种情况下会有问题:
- 线程1准备Pop操作,读取了栈顶节点
- 线程1将当前节点写到hazard pointer中
- 线程1再次读取栈顶指针
- 线程2将栈顶指针移走,并传递到垃圾收集线程
- 垃圾收集器扫描所有的hazard pointer节点,因为没有顺序一致性,可能看不到线程1的hazard pointer已经指向了这个节点
- 垃圾收集器删除了这个节点
- 线程1解引用这个节点,然后程序Crash
而如果有顺序一致性应用到hazard pointer的赋值和节点的修改,竞争就不会发生了。因为任意两个操作,所有线程看到的顺序都是一样的。如果线程2先移除这个节点,那么线程1第二次读时会看到一个不同的节点,也就不会去解引用它。假如线程1先将节点写到hazard pointer中,则垃圾收集器肯定可以看到这个值而不会去删除它。
性能
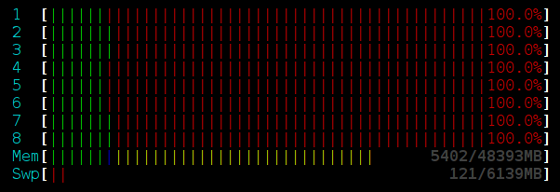
到现在我们解决了所有的问题。让我们看一下性能。测试使用的是一台8核Intel(R) Xeon(R) 处理器。每个线程的工作是随机的执行数量几乎相等的Push和Pop操作。每个线程不加限制的执行机器可以处理的操作。
我们修改栈顶的次数越多,CompareAndSwap失败的次数也会越多。一个简单有效的减少失败的方法是失败后Sleep一下,这可以调节Stack可以高效的处理数据。下面是每次失败后Sleep(250)的数据:
太好了,增加Sleep后栈的吞吐量增加了7倍。并且Sleep减少的处理器的消耗。让我们看一下处理器的使用情况:
加锁的栈:
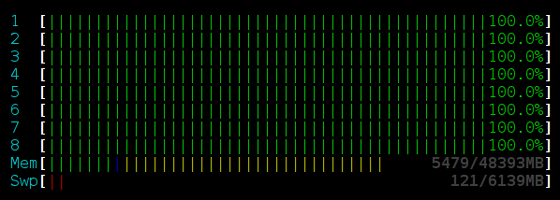
无锁的栈,不加Sleep:
无锁的栈,Sleep(250):
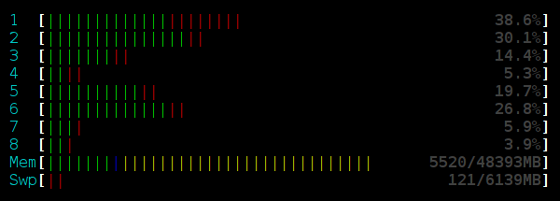
看起来无锁更好?等等,锁一样可以达到好的性能,我们不用std::mutex,我们使用Sleep(250)的自旋锁:
结果
大量数据时,额外的线程会降低吞吐量。Sleep可以降低操作冲突,增加吞吐量的同时减小处理器消耗。3个线程以上的性能没有变化。单线程是性能最佳的。
结论
无锁不会阻碍进度,但也并不会提高效率。当你想在你的项目中使用无锁算法时,切记要衡量值不值的-性能还有复杂度。
代码
加锁的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
1 #include <mutex>
2 #include <stack>
3
4 template<class T>
5 class LockedStack{
6 public:
7 void Push(T* entry){
8 std::lock_guard<std::mutex> lock(m_mutex);
9 m_stack.push(entry);
10 }
11
12 // For compatability with the LockFreeStack interface,
13 // add an unused int parameter.
14 //
15 T* Pop(int){
16 std::lock_guard<std::mutex> lock(m_mutex);
17 if(m_stack.empty()){
18 return nullptr;
19 }
20 T* ret = m_stack.top();
21 m_stack.pop();
22 return ret;
23 }
24
25 private:
26 std::stack<T*> m_stack;
27 std::mutex m_mutex;
28 };
|
Lock-Free的:
(垃圾收集相关的代码没贴出来)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
1 class LockFreeStack{
2 public:
3 // The elements we wish to store should inherit Node
4 //
5 struct Node{
6 boost::atomic<Node*> next;
7 };
8
9 // Unfortunately, there is no platform independent way to
10 // define this class. The following definition works in
11 // gcc on x86_64 architectures
12 //
13 class TaggedPointer{
14 public:
15 TaggedPointer(): m_node(nullptr), m_counter(0) {}
16
17 Node* GetNode(){
18 return m_node.load(boost::memory_order_acquire);
19 }
20
21 uint64_t GetCounter(){
22 return m_counter.load(boost::memory_order_acquire);
23 }
24
25 bool CompareAndSwap(Node* oldNode, uint64_t oldCounter, Node* newNode, uint64_t newCounter){
26 bool cas_result;
27 __asm__ __volatile__
28 (
29 "lock;" // This makes the following instruction atomic (it is non-blocking)
30 "cmpxchg16b %0;" // cmpxchg16b sets ZF on success
31 "setz %3;" // if ZF set, set cas_result to 1
32
33 : "+m" (*this), "+a" (oldNode), "+d" (oldCounter), "=q" (cas_result)
34 : "b" (newNode), "c" (newCounter)
35 : "cc", "memory"
36 );
37 return cas_result;
38 }
39 private:
40 boost::atomic<Node*> m_node;
41 boost::atomic<uint64_t> m_counter;
42 }
43 // 16-byte alignment is required for double-width
44 // compare and swap
45 //
46 __attribute__((aligned(16)));
47
48 bool TryPushStack(Node* entry){
49 Node* oldHead;
50 uint64_t oldCounter;
51
52 oldHead = m_head.GetNode();
53 oldCounter = m_head.GetCounter();
54 entry->next.store(oldHead, boost::memory_order_relaxed);
55 return m_head.CompareAndSwap(oldHead, oldCounter, entry, oldCounter + 1);
56 }
57
58 bool TryPopStack(Node*& oldHead, int threadId){
59 oldHead = m_head.GetNode();
60 uint64_t oldCounter = m_head.GetCounter();
61 if(oldHead == nullptr){
62 return true;
63 }
64 m_hazard[threadId*8].store(oldHead, boost::memory_order_seq_cst);
65 if(m_head.GetNode() != oldHead){
66 return false;
67 }
68 return m_head.CompareAndSwap(oldHead, oldCounter, oldHead->next.load(boost::memory_order_acquire), oldCounter + 1);
69 }
70
71 void Push(Node* entry){
72 while(true){
73 if(TryPushStack(entry)){
74 return;
75 }
76 usleep(250);
77 }
78 }
79
80 Node* Pop(int threadId){
81 Node* res;
82 while(true){
83 if(TryPopStack(res, threadId)){
84 return res;
85 }
86 usleep(250);
87 }
88 }
89
90 private:
91 TaggedPointer m_head;
92 // Hazard pointers are separated into different cache lines to avoid contention
93 //
94 boost::atomic<Node*> m_hazard[MAX_THREADS*8];
95 };
|