大模型推理 - Continuous batching和FasterTransformer结合
Contents
什么是continuous batch
介绍continuous batch之前,先说下Batch。Batch将多个请求合并一次处理,是提升GPU推理吞吐量(throughput)的一种方法。其原理有三:
- 并发提升,提升了GPU核的利用率
- 显卡带宽&算力的复用,比如矩阵乘多batch时权重读取的带宽复用
- Kernel Launch次数减少,有效载荷提升
传统的Batch是模型粒度的,将多个请求合并在一起,然后调用模型的推理接口,完成后在解batch,将结果返回给各个请求。这种方式对于大语言模型推理并不适用,因为大模型的推理有2个特点:
- 生成长度不可知
- 一个请求的时间可能很长
这2个特点导致,传统的Batch方案会导致极大的算力浪费,系统大部分时间都在处理较长的请求,如图所示:
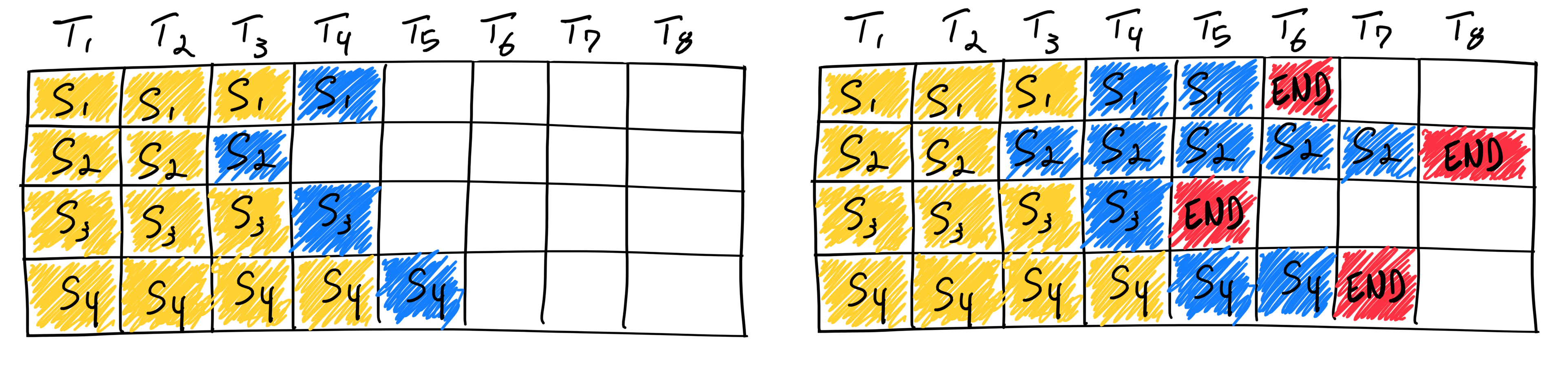
各个框架都注意到这个问题,23年5月 TGI提出了Continuous batching的解决方案,后vllm 实现了PagedAttention更加强了Continuous batching的能力。除了Continuous batching,lmdeploy里面的Persistent Batch,TensorRT里面的Inflight Batch都是相似的思路。
Continuous batching是专门提升大语言模型吞吐量的一种组batch方式,相比于传统的模型粒度的组batch,是在迭代阶段(生成token)组batch,完美的规避了请求长短不一的问题。如图所示:
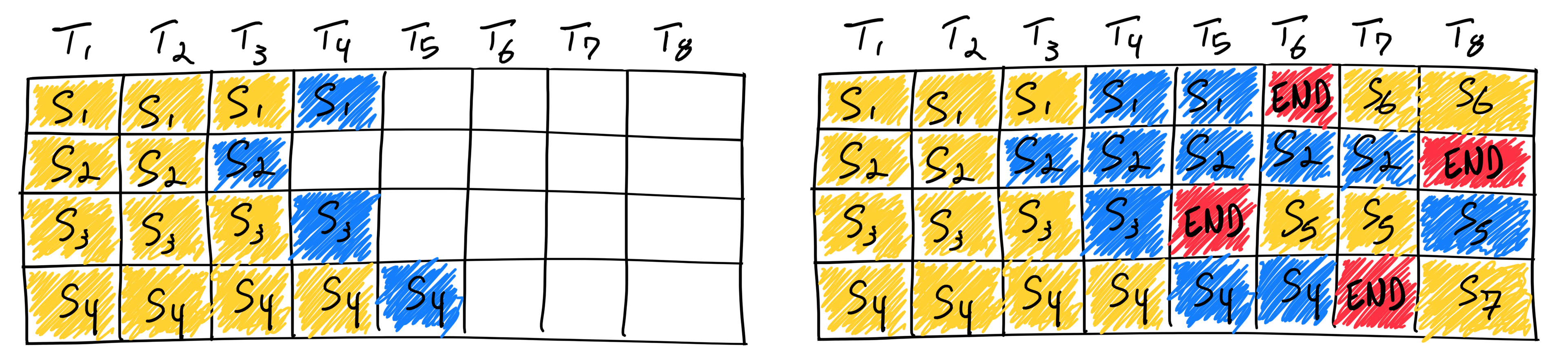
除了batch,有些同学询问是否可以通过多并发来提升大模型吞吐量,回答是提升有限。前面batch提升吞吐量的三个原理,多并发只对第一个原理有帮助,而在大模型推理领域,原因2带宽也是很关键的。
另外需要注意吞吐量和延迟(latency)是矛盾的,Batch在提升吞吐量的同时,往往伴随着延迟的增加。
基于FasterTransfromer的Continuous batch
FasterTransfromer(简称FT)是英伟达开源的针对transformer结构的加速引擎,在单batch场景下有非常优秀的表现,但只支持普通batch, 且有诸多限制,所以早在VLLM以前我们就计划优化FasterTransfromer的batch。正好vllm的成功给了我们启发和借鉴。
有人会说Vllm已足够优秀,基于FasterTransformer新造轮子是否有意义? 答案是非常有必要,就像简单的一道西红柿炒蛋,食材一样,但锅具不同,厨师各异, 味道天地之别。在大模型GPU推理上,为性能计,C++这口锅显然优于Python(vllm基于python),加上我们针对业务场景优化,性能超越Vllm是水到渠成的。最终测试7b下吞吐量达到vllm的2倍(23年8月份测试),后续调优算子后在66B规模下单batch速度达到TGI的1.4倍,吞吐量达到TGI的3倍 (11月测试,公司数据比较敏感,详细数据不便披露)。
对比vllm,FT的方案有如下优化:
- 无python的GIL问题,观察vllm, batch>16时cpu占用率100%,并发越高,cuda util越低,GIL的问题非常明显
- 预分配显存内存 在服务启动时预分配资源,减少推理过程中的动态开销。
- 更高效的算子,比如qkv拆分+保存cache+bias融合为一个算子,更快的sample算子
- 调度层细节优化 比如 一、获取结果用内核信号量代替vllm里面的map查询,二、仅任务变更时才刷新mask, 三、alibi全局计算一次 等等
当然我们是参考vllm实现了这些功能,有后发优势,vllm中依然有一些优秀的feature: flashattention, tokenizer增量解码等值得借鉴。
PagedAttention
在PagedAttention以前,kv cache一般基于output_length预分配的,output_lenght往往很大,导致显存占用很大,比如Bloom 175B output_lenght=1024时显存占用3.9G。但实际生成的output_lenght往往很小,导致显存的巨大浪费。显存的浪费导致,导致无法组很大的batch, 吞吐量上不去。
所以vllm发明了PagedAttention,减少kv cache显存浪费,从而可以配合continuous batch提高batch数,提升吞吐量。核心原理如图:
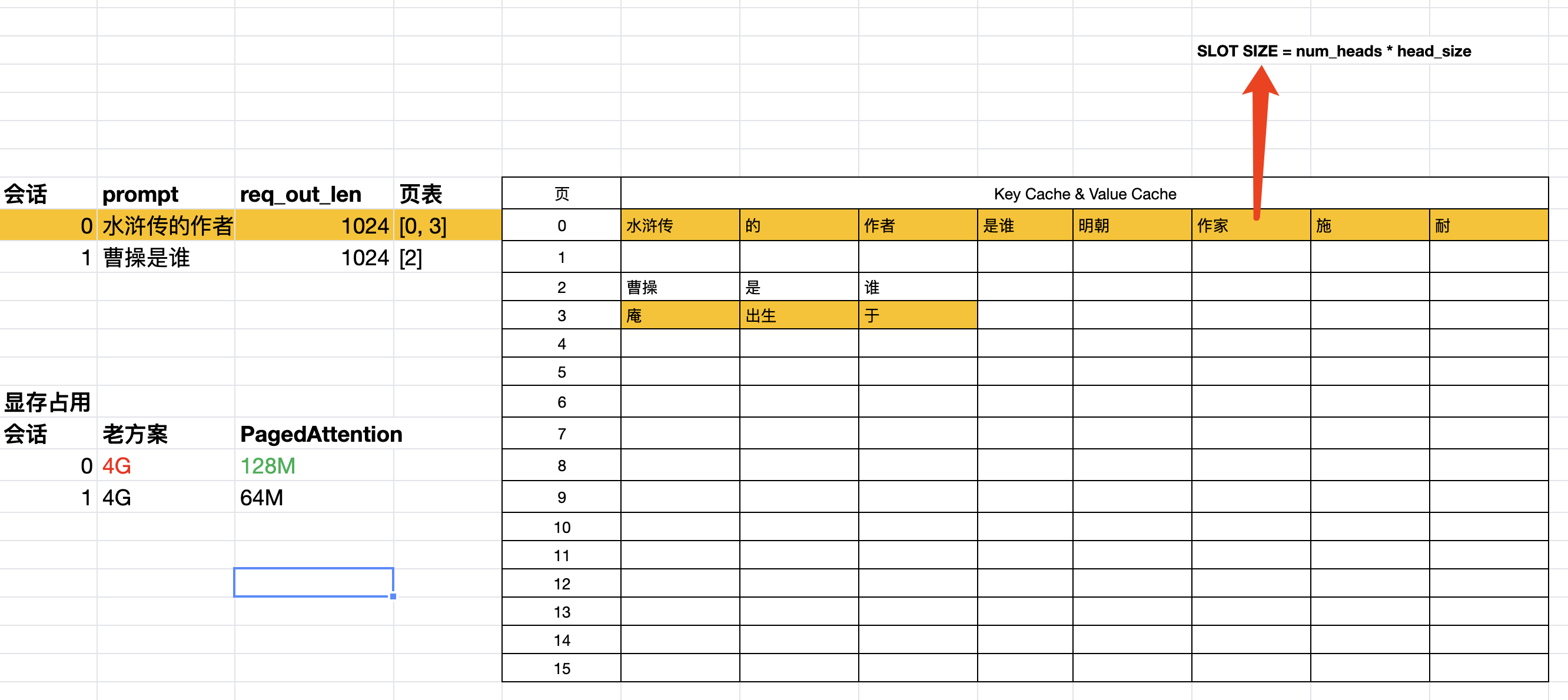
keycache和valuecache是独立存在的,以keycache说明
- cache申请为连续的显存
- 逻辑上上以页来划分,每个页有Block_size个槽位(slot), 每个槽位对应一个Token
- 会话在生成过程中,动态按页申请显存。每个会话维护一个页表
- 推理时将页表信息传入MHA算子,即为PagedAttention。
这里可以看出PagedAttention的优势是按页分配无浪费,但引入了一个问题,页是动态申请的,会话进行到一半申请不到页怎么办?这个就是后面调度要解决的了。
架构解析
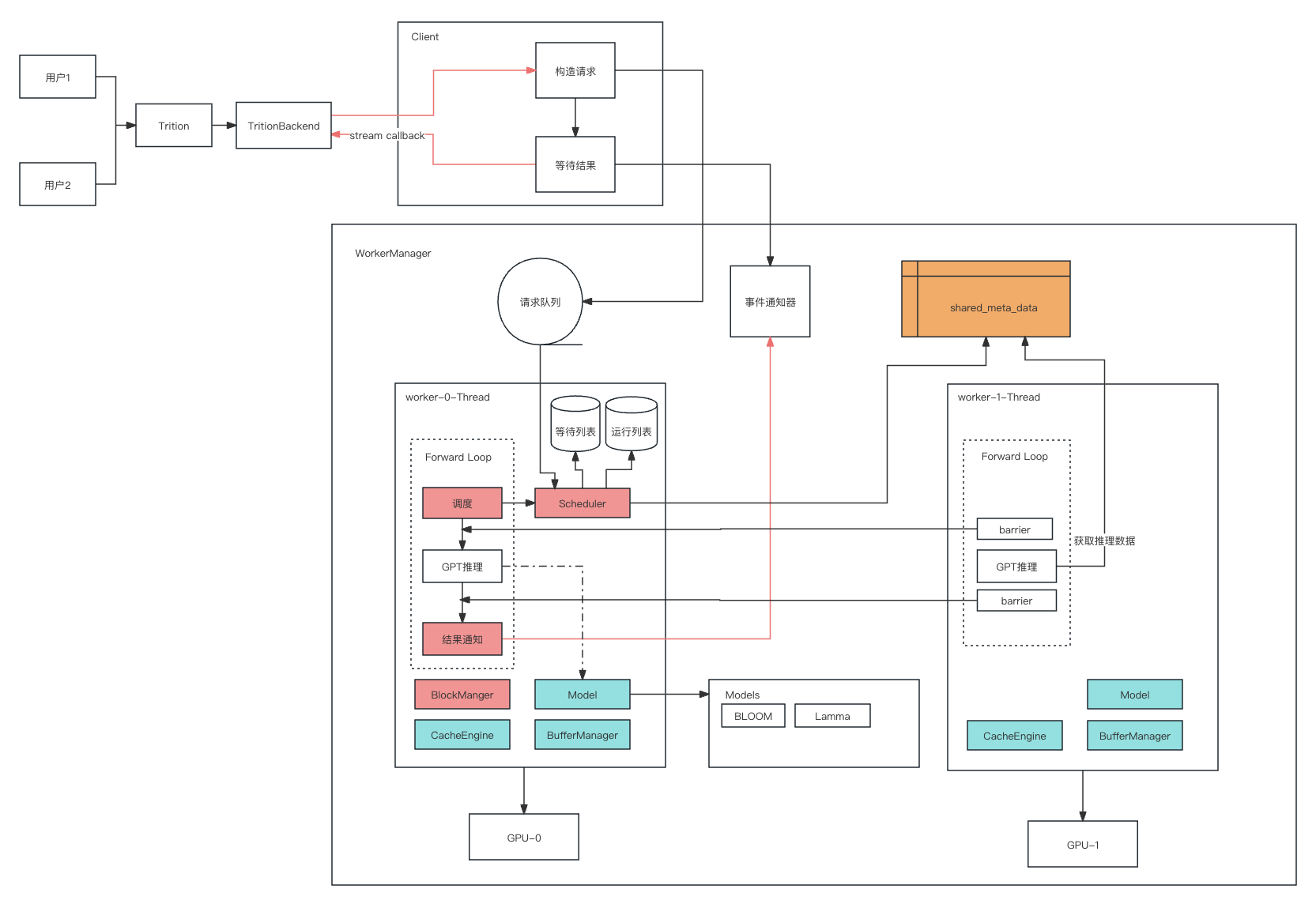
Client & TritionBackend
这2个模块是接口层,接收服务端的请求,构造一个Task, 并添加到工作队列中,然后就不停的等待新Token的产生,直到结束。结果流式的推送到TritionBackend中。
TritionBackend进行改造,兼容老版本接口,服务端或triton可以直接运行。
WorkerManager
worker的协调者,负责初始化worker和创建多worker间的共享数据
Worker
batch推理的具体协调和驱动者。每个卡一个worker, 每个worker中有一个model和cacheEngine, 卡0的worker额外有Scheduler和blockManager,用来调度Task组Batch,驱动model进行模型推理。
CacheEngine & BlockManager
CacheEngine是kvcache物理层面的管理者,作用有2:
- 启动时预分配kvcache,每一层的cache是一个连续的显存(keycache和value分别是独立的地址)
- 当调度发生swap时,处理显存和内存的SwapIn & SwapOut
BlockManager是kvcache逻辑层面的管理者,主要是维护闲置页列表:
- 当会话来申请时,有闲置页则给它,移出闲置页列表
- 会话结束,再把页还回来,加入闲置页列表
BufferManager
推理过程中衔接流程的buffer很多,比如input_ids_buf, logits_buf, qk_buf, 这些除了attention过程中的q*k的qk_buf(num_head * seq_len * seq_len)外一般都比较小。 BufferManager负责部分buffer,另外一部分buffer由model自行维护。
Scheduler
调度器根据资源负载动态组Batch的过程,资源在物理上是显存,逻辑上是kvcache和buffer。每轮迭代之前都会进行调度,以先来先服务原则,调度器维护3个队列:
- waiting list 新添加的会话会进入waiting, 如果会话可以获取到资源,则进入running
- running list 表示当前推理的会话,即为组的batch,若running中的会话申请不到资源, 则移出running, 进入waiting
- swaping list 回答前面的问题“会话进行到一半申请不到页怎么办?”,swaping就是解决这个问题的。
实际生成过程中output_len不可预知,为了追求吞吐,kvcache是很有可能发生超卖的, 此时有两种策略,一是丢掉cache从头计算 二是 cache暂时从显存移入内存,后续再移回。目前我们实现的是方案二。
如果所有running的会话都申请不到资源,则将running或waiting中的一个会话移入swaping。 等有资源时,再将swaping的任务移入running。
swaping list的变更,伴随着显存和内存的SwapIn&SwapOut, 对性能的影响很大。
对抗Swap
因为swap对性能影响较大,所以vllm中可以配置--max-num-seqs来限制最大Batch数,但这个值大了会Swap, 小了吞吐量上不去,并且通过batch来限制粒度太大。
LightLLM提出了一种改进方法:Efficient Router,策略如下:
- kvcache支持的token总数为:
max_allocate_total_token_num, 设置一个调度token总数:max_schedule_total_token_num - 当waiting的会话要进入running list时,可以根据当前的running list和新会话的input_token_num和ouput_token_num,计算添加新会话后所需最大token总
max_need_total_token_num - 如果
max_need_total_token_num<max_schedule_total_token_num并且可以申请到资源则允许进入running list
Efficient Router可以更好的平衡batch数和swap的矛盾,若设置max_schedule_total_token_num为max_allocate_total_token_num则永远不会swap,但这个值同样不容易配置,大了会Swap, 小了吞吐量上不去。
所以我们基于Efficient Router可以再进行一次优化,借鉴TCP拥塞控制的和式增加,积式减少, 根据负载动态的调整 max_schedule_total_token_num:
- 设置
max_schedule_total_token_num初值为max_allocate_total_token_num - 调度时若
max_need_total_token_num大于max_schedule_total_token_num且kvcache页的利用率小于90%, 则max_schedule_total_token_num + 100。 - 若发生swap,则
max_schedule_total_token_num - 1000。
Model
Model是具体模型的实现,比如Bloom、Lamma。欲支持contiuous batch最主要的工作是支持PagedAttention, 其Forward方法相比于之前的循环迭代生成token, 变成了每次只生成一个Token(每个batch一个)。流程如下图:
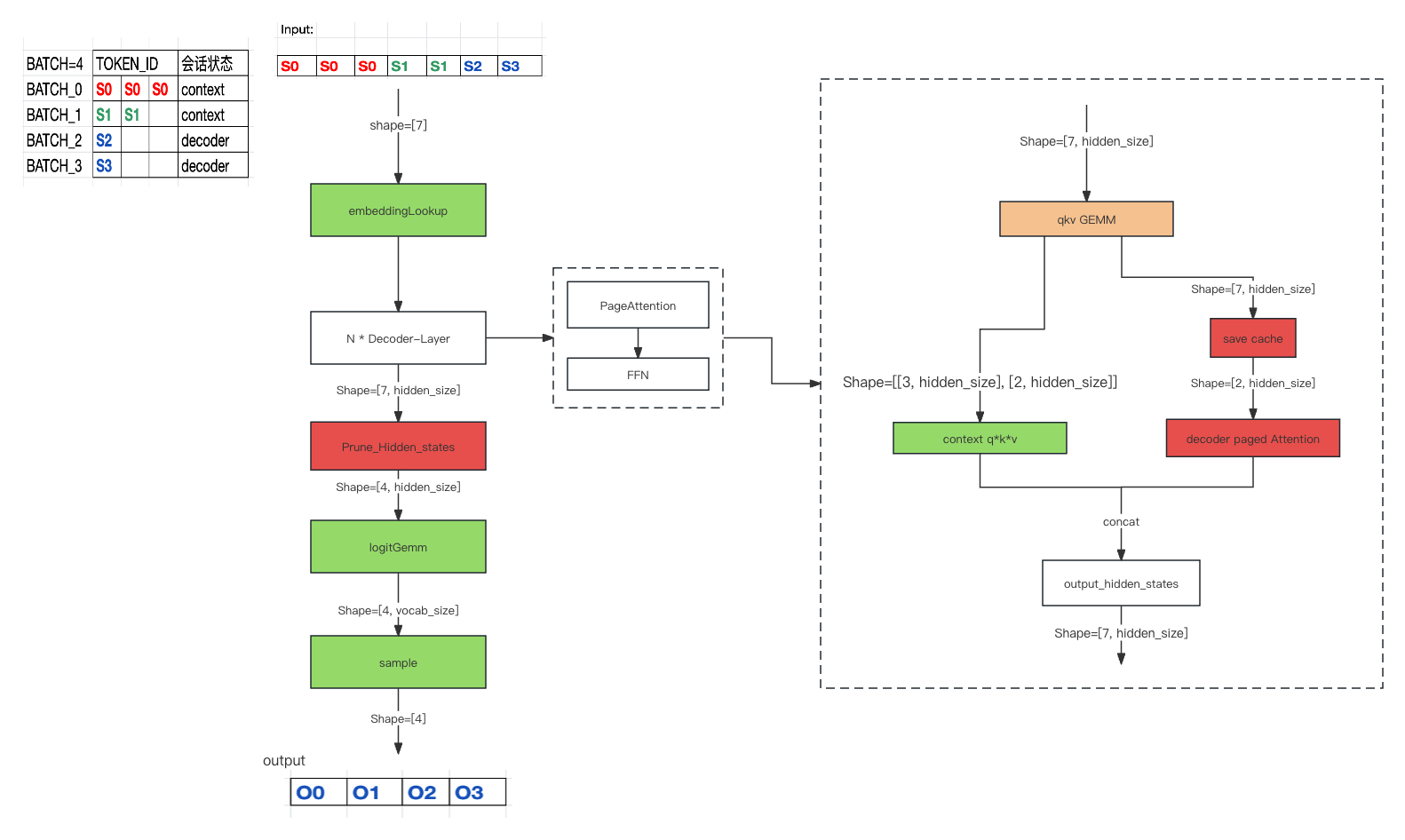
框架抽象好Model的接口,我们可以任意的添加新的模型,新的模型无需关注调度等逻辑。
显存预分配
预分配目的有2:
- 为性能计
- 防患未然 定位过多次input_len过长OOM导致的Crash, 预分配提前检查显存是否满足业务方最大值情况,不满足则启动时报错。
那如何预分配呢?用到显存的3个模块:CacheEngine、BufferManager和Model。显存取决于input_token_len和output_token_len,通过业务配置的max_input_token_len和max_output_token_len,计算出三个模块在单batch下需要的显存大小,然后根据系统剩余显存,计算出可分配的malloc_max_input_token_len和malloc_max_output_len, 并用这2个值调用3个模块申请显存。
License 知识共享署名 3.0 中国大陆许可协议